Module 5 -- Vector Spaces -- Continued
Index
- Eigenvalues and Eigenvectors
- The Cayley-Hamilton Theorem
- Symmetric matrices
- Diagonalization of matrices (symmetric matrices)
- Orthogonal Matrix
- Gram-Schmidt Orthogonalization
Eigenvalues and Eigenvectors
https://www.youtube.com/watch?v=PFDu9oVAE-g (must watch this)
Given a square matrix,
where
In words:
An eigenvector of
Breakdown of the Equation
: the vector should not be the zero vector can be positive/negative/zero/complex - All vectors that satisfy this are eigenvectors for eigenvalue
.
How to find Eigenvalues and Eigenvectors
Step 1: The Characteristic polynomial
Rewriting:
Nontrivial solutions (
This is called the characteristic equation.
- The solutions
are eigenvalues.
Step 2: Find Eigenvectors
For each eigenvalue
- Solve (
) - The set of all such nonzero vectors
is the eigenspace for eigenvalue .
Detailed Example
Let's use :
Step 1: Find the eigenvalues
https://www.youtube.com/watch?v=e50Bj7jn9IQ (This is a video showing a quick trick for calculating eigenvalues, since the more bigger a matrix is, the more complex the equations will be, might get harder to solve.)
We can get that from the characteristic equation :
First:
Now,
Now we equate that to zero.
And after doing some basic factorization:
So the eigenvalues are:
Step 2: Find eigenvectors for each eigenvalue
From the equation:
For
Now we equate the rows and columns to a vector
Applying to both the rows, we get two equations:
From the first equation:
And from the second equation:
So all vectors are of the form:
(or any scalar multiple) are eigenvectors with eigenvalue
Now, for
So from either row we get the equation:
So,
So, all vectors of the form:
(or any scalar multiple) are eigenvectors with eigenvalue
Why Are Eigenvectors and Eigenvalues Important?
- Reveal the “axes” along which
acts in the simplest way. - Used in diagonalization, stability analysis, differential equations, quantum mechanics, Google’s PageRank, machine learning and more.
The Cayley-Hamilton Theorem
https://www.youtube.com/watch?v=TNxmupelc-4&list=PLF-vWhgiaXWPZ7Ogw6zIZMg4aqUXEwrnJ&index=9 (must watch)
What is the Cayley-Hamilton Theorem?
- Every square matrix A satisfies its own characteristic polynomial
. - If
, then
(the zero matrix).
Or, in very very simple terms,
For a given matrix
which is often called the characteristic equation.
Example
Let's use the one given in the video.
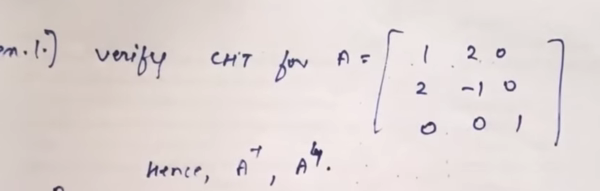
Given matrix:
Now, there are two ways to go about this.
Step 1: Write the characteristic equation:
Method 1: We find the eigenvalues, substitute them back into the characteristic equation's LHS and then find out if it equates to the RHS.
Method 2: We follow the steps given in the video.
Let's try method 1.
Step 2: Find the eigenvalues
Now, find the determinant of this matrix:
Now it is gonna be a massive pain to solve this equation and find the damn roots.
And I am not kidding about this.
Skip ahead to Let's use the given roots to see if method 1 works in theory or not. to see if this approach pans out or not, and then I will show the easy approach to continue from once we have found the equation (from the video, method 2)
Here's what a search on perplexity did, a massive rabbit hole.
Perplexity(GPT 4.1)'s solution for the cubic equation.
Ah yes now I caught the sign mistake, lamda^3 should have a negative sign. Now then that we have this equation, what would be it's roots?
(I had previously made an error in the sign for
Great! Now that we have the correct characteristic equation:
Let's find its roots.
Analytical Approach
This cubic is not easily factorable with integers, so let's look for rational roots using the Rational Root Theorem:
Possible rational roots:
-
Try
: -
So,
is a root!
Now divide the cubic by
Synthetic Division
Divide
So, quotient is:
Therefore:
Roots of the Quadratic
Final Roots
Let's use the given roots to see if method 1 works in theory or not.
So we have the roots as:
which are the eigenvalues.
The CHT says that:
For a given matrix
or it should result in a
However, unfortunately that's not the case, as you will see below.
Applying into equation:
For
which unfortunately is not the null matrix.
For
which also, again, is not the null matrix.
For
which also, again, is not the null matrix.
Key takeaway?
Sure the roots didn't pan out. But:
We don't have to use this method from the video:
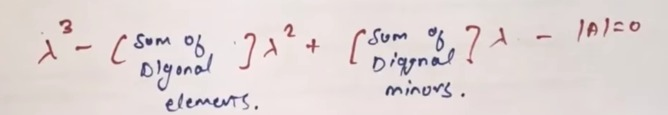
which will lead into all sorts of messes to find out the equation of:
which is almost the same in the video:
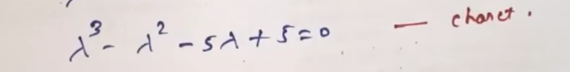
that we can just achieve if we multiply both sides by -1
But, for continuity's sake, let's not do that and continue with our previously achieved equation:
Remember the end goal here is to check if:
equates to zero or not.
So, how do we proceed after this?
We just replace
from the equation:
which is derived from:
So the equation becomes:
Now we verify the LHS part only to see if it equates to zero or not.
Also we must add a tweak:
since we are replacing the eigenvalues with entire matrices, every term must be on the same size of the replacement matrix.
Since the last term was just a constant, we can write
Why did we do this?
A scalar like 5 cannot be added to or subtracted from a matrix; the objects must be conformable. The identity matrix I acts as the multiplicative identity for matrices, so the constant term is represented as 5I (a matrix with 5 on the diagonal and 0 elsewhere). This way every term is a 3×3 matrix and they can be summed.
So,
Welp, the matrix multiplication is gonna be a pain lol.
So,:
Now,
And lastly,
and:
Finally arranging them all together:
which is now, the null matrix or zero matrix.
Thus:
or for a better statement:
is proved, which verifies the Cayley-Hamilton Theorem for this matrix.
Symmetric matrices
https://www.youtube.com/watch?v=vSczTbgc8Rc (watch the first two halves of the video to understand all about symmetric matrices)
Definition and basic properties
- A real matrix
is symmetric if , where is the transpose of - Entries mirror across the main diagonal:
. - Symmetric matrices are always diagonalizable over R and have real eigenvalues.
- Their eigenvectors are orthogonal i.e. perpendicular to each other.

See how the elements on both sides of the diagonal, except the starting and ending element are the same? These are called symmetric matrices.
Diagonalization of matrices (symmetric matrices)
https://www.youtube.com/watch?v=sikqqbbJUXc&list=PLF-vWhgiaXWPZ7Ogw6zIZMg4aqUXEwrnJ&index=13
For a matrix
where:
Steps to obtain the modal matrix.
- Write the characteristic equation
- Solve L.H.S to get a characteristic equation of type
- Instead of replacing
with , solve the equation to find the roots i.e. the eigenvalues. (Refer to previous sections) - Substitute the eigenvalues in the derived equation to get the eigenvectors in form of:
Now, the modal matrix
By writing each eigenvector as the column vectors of the modal matrix.
Then we can calculate the inverse, plug them in the formula, and after doing the math :
We should get a matrix like this
which is the diagonal matrix. If we don't get this matrix, then it means the given matrix is not diagonalizable.
Example
For example please refer to the examples in the video :
https://www.youtube.com/watch?v=sikqqbbJUXc&list=PLF-vWhgiaXWPZ7Ogw6zIZMg4aqUXEwrnJ&index=13
Orthogonal Matrix
https://www.youtube.com/watch?v=wciU07gPqUE&t=117s (watch this part)
An orthogonal matrix is basically a matrix whose column vectors are orthogonal (perpendicular to each other), and also their dot product would equate to zero.

And the column vector's length is always one, hence they are unit vectors.
For example if we take the column vector:
we can find the length of this column vector by taking the square root of the sum of the squares of the elements:
Same goes for the other column vector, which means these are unit vectors.
Gram-Schmidt Orthogonalization
https://www.youtube.com/watch?v=UOZjINOGLog (must watch)
https://www.youtube.com/watch?v=rHonltF77zI (another way to visualize this)
https://www.youtube.com/watch?v=tu1GPtfsQ7M (example of method 2)