Module 1 -- Basic Linear Programming Problems (LPP) and Applications
Index
- Pre-requisites before heading into Linear Programming
- Topic 1 Introduction to Optimization
- Topic 2 Mathematical Formulation of Linear Programming Problems.
- Topic 3 Feasible Solutions and the Feasible Region
- Topic 4 Graphical Method of Solving Linear Programming Problems
- Example 1 and Example 2
- Basic Solution and Basic Feasible Solution
- Degenerate Solution (or Degenerate-Basic Solution) and Non-Degenerate Solution (or Non-Degenerate-Basic Solution)
- Convex Sets
- The Simplex Method of solving Linear Programming Problems
- The Algorithm of Simplex Method
- Charnes' Big-M Method
- Duality Theory
Pre-requisites before heading into Linear Programming
Topic 1: Introduction to Optimization
Before diving into Linear Programming, let's understand the fundamental concept of optimization.
What is Optimization?
Optimization is the systematic process of finding the best possible solution to a problem from a set of available alternatives. In mathematical terms, it means finding values that either maximize or minimize a particular function while respecting certain limitations.
Think of optimization problems everywhere in real life: a company wants to maximize profit while staying within budget constraints, a delivery service wants to minimize travel time while visiting all customers, or a factory wants to minimize production costs while meeting demand.
Key Elements of Any Optimization Problem
Every optimization problem has three essential components :
Decision Variables: These are the quantities you can control or modify to find the best solution. For example, if a bakery produces cakes and cookies, the number of cakes (let's call it
Objective Function: This is the mathematical expression you want to maximize or minimize. For the bakery, if each cake gives $10 profit and each cookie gives $5 profit, the objective function would be: Maximize Profit =
Constraints: These are the restrictions or limitations that must be satisfied. The bakery has limited flour, sugar, oven time, etc. These limitations become constraints in mathematical form.
What Makes It "Linear Programming"?
This brings us to a special type of optimization called Linear Programming (LP). Linear Programming is a method used when both the objective function AND all constraints can be expressed as linear equations or inequalities.
The word "linear" here is crucial and connects directly to our (if you studied the whole section of Mathematics - 1A and Numerical Methods), linear algebra knowledge. In linear programming, all relationships between variables are linear—meaning variables appear with power 1 only, and terms are added or subtracted (no multiplication of variables with each other, no squares, no fractions with variables in denominators).
The word "programming" here doesn't mean computer programming; it's an older mathematical term meaning "planning" or "scheduling".
Topic 2: Mathematical Formulation of Linear Programming Problems.
Now that we understand the three key components (decision variables, objective function, constraints), let's see how to write them mathematically and understand the different forms they can take.
General form of an LPP
A Linear Programming Problem in its general form looks like this:
Optimize(Maximize or minimize):
Subject to:
where
Components Breakdown
Now let's understand what the components above actually mean:
Objective Function: The function
represent the contribution of each decision variable to your goal (like profit per unit, cost per item, etc.).
Constraints: These are the linear inequalities or equations that limit your choices. They can be of three types:
Non-negativity Constraints: In most real-world problems, decision variables cannot be negative. You can't produce
Standard Form vs Canonical Form
For solving LPPs using algorithms (like the Simplex Method we'll learn later), we need to convert problems into specific standardized formats.
Canonical Form requires :
- Objective function must be of maximization type
- All constraints (except non-negativity) must be ≤ type
- All variables must be non-negative
- Right-hand side values must be non-negative
Standard Form requires :
- All constraints must be equalities (equations, not inequalities)
- This is achieved by introducing slack variables for
constraints and surplus variables for constraints - All variables (including slack/surplus) must be non-negative
Slack and Surplus Variables
To convert inequalities to equalities, we introduce new variables :
Slack Variable: Added to a
Surplus Variable: Subtracted from a
Topic 3: Feasible Solutions and the Feasible Region
Types of Solutions
Feasible Solution: Any set of values for decision variables
Infeasible Solution: Any solution that violates at least one constraint. These solutions are not acceptable.
Feasible Region (or Feasible Set): The collection of all feasible solutions forms a region in n-dimensional space. For two-variable problems, this is a region on the 2D plane.
For example in this diagram here:
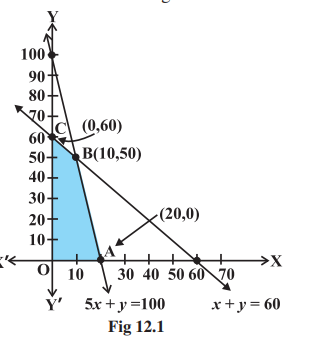
The shaded region OABC is the feasible region.
Optimal Solution: Among all feasible solutions, the one that gives the best (maximum or minimum) value of the objective function is called the optimal solution. An LPP can have a unique optimal solution, multiple optimal solutions, or no optimal solution (unbounded or infeasible cases).
Topic 4: Graphical Method of Solving Linear Programming Problems
https://www.youtube.com/watch?v=Bzzqx1F23a8 (must watch)
Step-by-Step Procedure: Corner Point Method
Step 1: Graph all constraints
Plot each constraint as a line on the xy-plane. For an inequality like
Step 2: Identify the feasible region
The feasible region is the area where all constraints overlap, including the non-negativity constraints
Here's few example images of a convex polygon:
Rules for finding the feasible region (very important)
- If both the constraints have
sign, then the feasible region will be to the left and below of the both the constraints, in the region where both of them overlap.
For example, this:
- If both the constraints have
sign, then the feasible region will be to the right and above of both the constraints, making an unbounded region.
For example this:
- If the signs of the constraints are mixed, i.e. one constraint having a
sign and the other having a sign of vice-versa we would need to follow the appropriate rules for both the constraints to find the feasible region somewhere between the two constraints.
For example this:
Step 3: Find the corner points (vertices)
Corner points are where two constraint lines intersect. You can find them by solving pairs of equations simultaneously.
Step 4: Evaluate the objective function at each corner point
Calculate the objective function (for example if it is
Step 5: Determine optimal solution
-
Bounded region: The maximum (or minimum) value from Step 4 is your optimal solution.
-
Unbounded region: If the region extends infinitely, you need to verify whether a maximum/minimum exists by checking if the half-plane
(for maximum) or (for minimum) has common points with the feasible region.
Key Theorems
Theorem 1: If an optimal solution exists, it must occur at a corner point of the feasible region.
Theorem 2: If the feasible region is bounded, then both maximum and minimum values exist and occur at corner points.
Important: If two corner points give the same optimal value, then every point on the line segment joining them is also optimal (multiple optimal solutions).
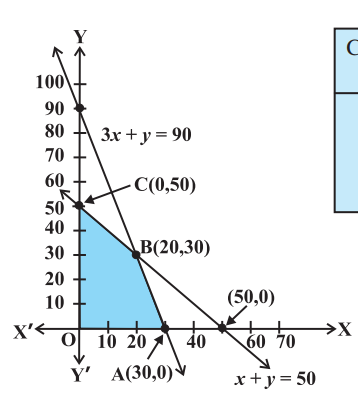
Example 1
Problem: Maximize
Subject to:
,
Solution:
Step 1: Graph the constraints:
- Line 1:
.
In order to graph this line we will set both
- Line 2:
Setting
And setting
- Line 3:
, is just the origin point.
Step 2: Find the feasible region
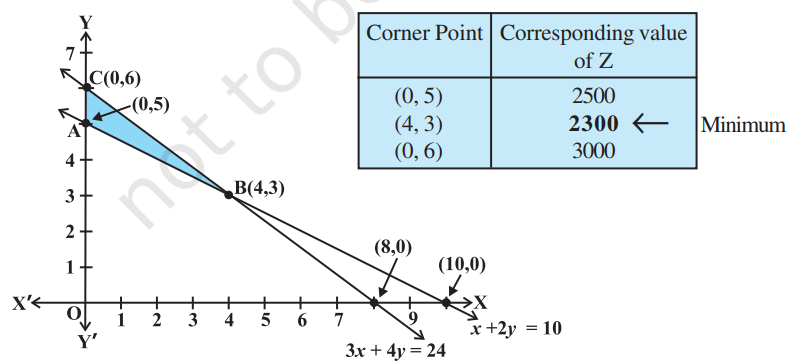
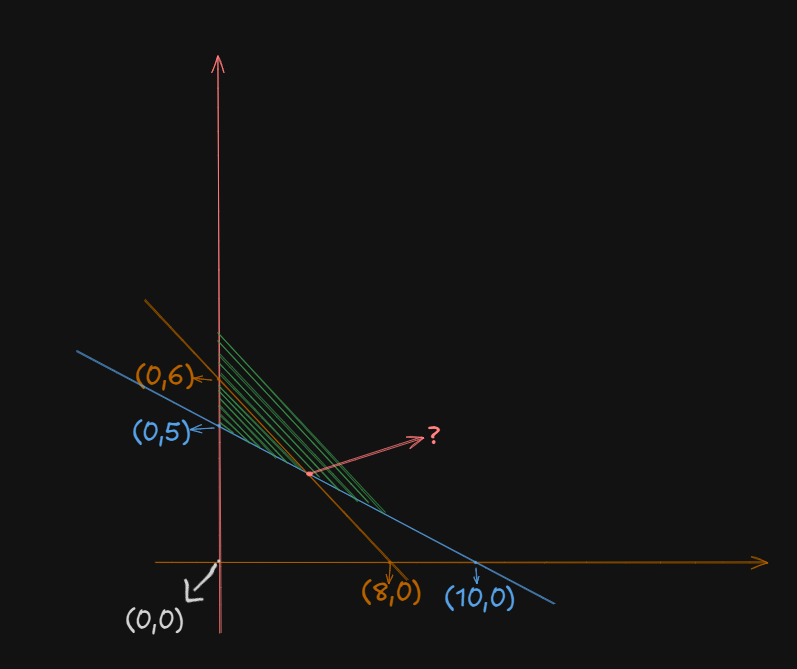
So, after plotting these lines, we find the feasible region as the region under which all the constraint lines overlap. In this case this one will be a neat bounded region:
Assuming:
as point as point - The orange intersection point as
, which we have to calculate. as point
The feasible region is
Step 3: Find all corner points
The only left to find is point B.
We can find out the intersection point by solving the two inequalities equations and getting their
So we have:
(Ignoring the
A simple substitution would suffice here.
From
If we set:
From:
Now substituting the value of
So we have:
as point
So, all our corner points are:
Step 4: Evaluate the objective function at corner points
So we evaluate
At origin
At point A
At point B
At point C
So,
| Corner Point | |
|---|---|
| O(0, 0) | 0 |
| A(30, 0) | 120 (Maximum) |
| B(20, 30) | 110 |
| C(0, 50) | 50 |
Step 5: Find the maximum value from all the evaluated values of the objective function.
The maximum value is 120 at point (30, 0).
This means: produce 30 units of
Here's the full reference of the example used:

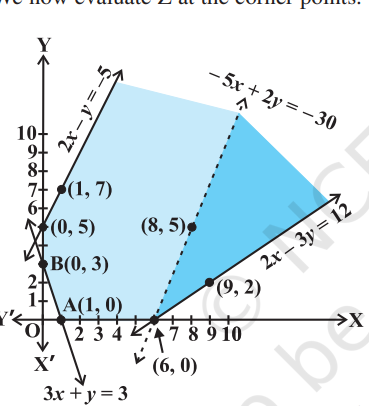
Example 2
Given objective function:
Subject to constraints:
,
For the first constraint, setting
And for
For the second constraint, setting
And for
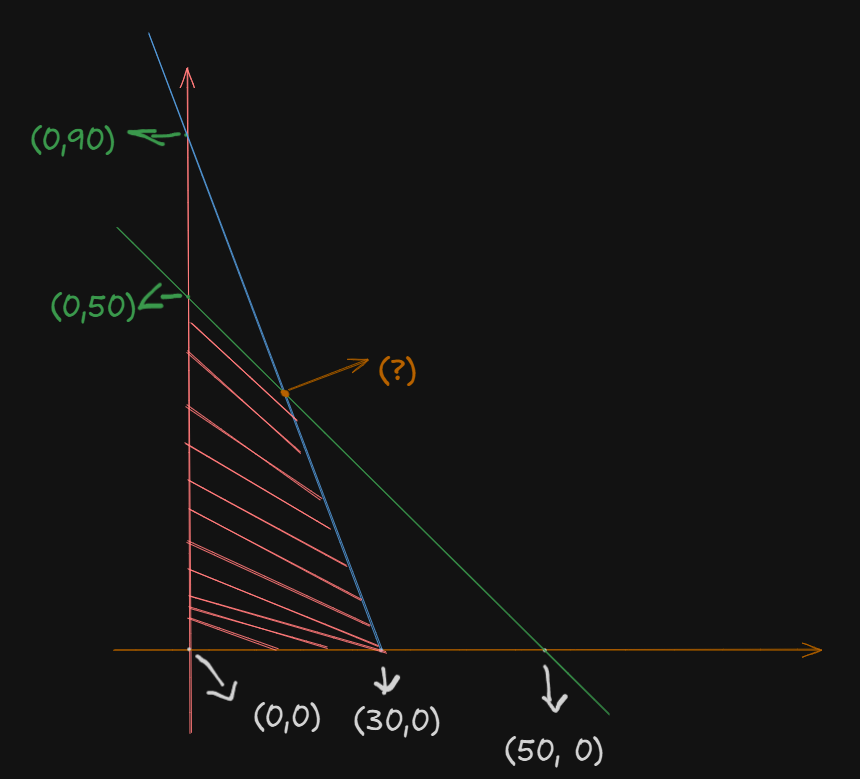
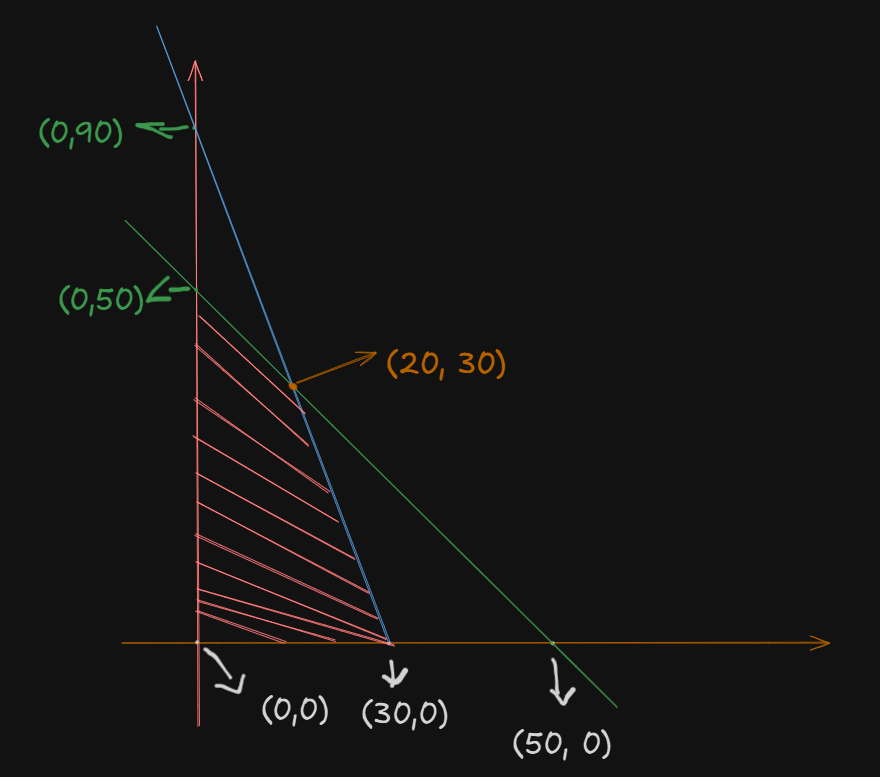
Now, we need to plot the feasible region. This one will be an unbounded region since both the constraints have the
So, we get this:
Now, we have to find that intersection point.
A simple substitution operation will suffice here:
Setting
In the second constraint:
Applying
So, we get the intersection point at
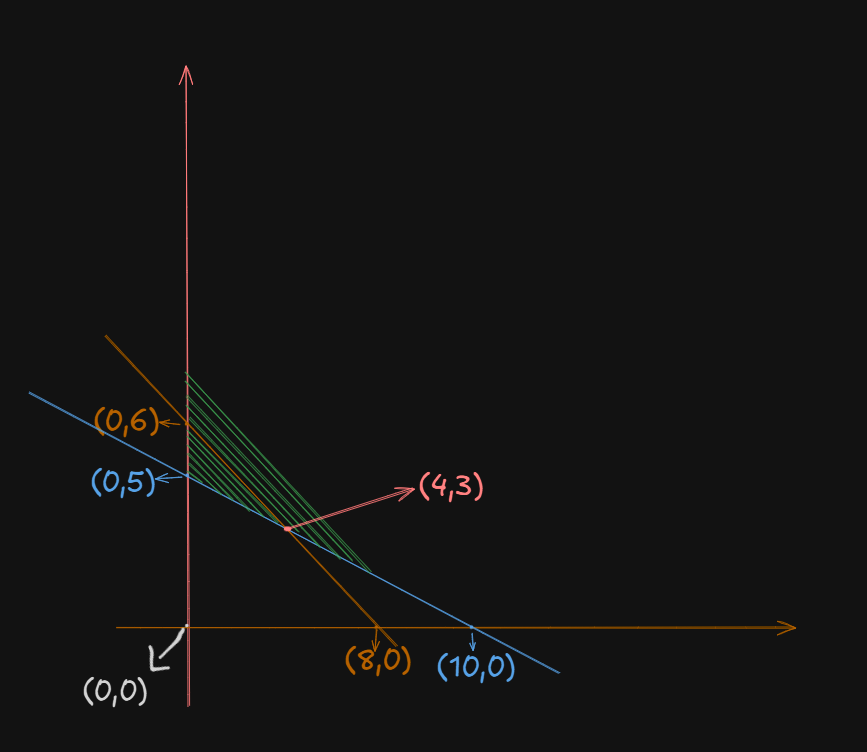
Now, to find the minimum, we evaluate
At point
At point
At point
So, the smallest value is
Basic Solution and Basic Feasible Solution
Converting to Standard form -- The how and the why.
Standard form is needed because the Simplex Method (an algebraic method we'll learn later) requires all constraints to be equations, not inequalities. The graphical method works fine with inequalities, but algebraic methods need equations.
Think of it like this: In linear algebra, when you solve systems of equations like
A simple example
Problem: Maximize
Subject to:
Since it has a
So, in standard form, the constraints are:
where
What are slack variables? They represent the "unused" amount of a resource. If the constraint is "at most 50," and you use 30, then the slack is 20.
Counting Variables: The Key to Everything
Now we count:
- Number of equations (
) : 2 (we have 2 constraints) - Number of variables (
): 4 ( , , , )
From linear algebra: A system with more variables than equations
Basic vs Non-Basic Variables: The simple rule
In a system with
- Choose
variables to solve for: these are basic variables. - Set the remaining
variables to zero: these are non-basic variables.
From our example:
So,
That gives us:
- 2 basic variables
- 2 non-basic variables
Why do this?
Because when you have more variables than equations, you need to "fix" some variables to find a specific solution. By setting
Now let's solidify our understanding by finding one basic solution.
So we had:
So, if we choose let's say
Then the remaining two variables
So, the constraints now become:
Thus the basic solution (the solution to the constraints) is:
Since all values are
Difference from regular feasible solutions
Regular feasible solution: ANY solution that satisfies all constraints. For example:
, , satisfies both constraints , also works
So there are infinitely many solutions.
whereas,
Basic feasible solution: A special feasible solution where exactly
, (we already did this just now) , - And so on, but only a finite number of basic feasible solutions exist.
The Key Insight
Basic feasible solutions are the corner points we've been graphing! At each corner point.
- Exactly 2 variables are non-zero (basic)
- Exactly 2 variables are zero (non-basic)
This is why we only check corner points in the graphical method.
Now, as to part of "where do the basic variables need to be selected from, can it be from one constraint, or both?"
You can choose basic variables from anywhere (same constraint, different constraints, doesn't matter) as long as their corresponding columns in the constraint matrix are linearly independent. We learnt about linear independence back in Module 3 -- Matrices#Linear Independence
However, if you are worried about the time it would take to test the combination of variables:
In practice:
-
Slack variables often form a natural basis because they give an identity matrix (best for basic variables)
-
The Simplex Method algorithmically ensures the chosen basis is always valid.
-
You don't manually check every combination - algorithms do this for you.
Degenerate Solution (or Degenerate-Basic Solution) and Non-Degenerate Solution (or Non-Degenerate-Basic Solution)
A basic feasible solution (BFS) is called:
Non-Degenerate BFS: When all basic variables are strictly positive (greater than zero).
Degenerate BFS: When at least one basic variable equals zero.
That's basically it.
Why Does This Matter?
Degeneracy can cause problems in the Simplex Method :
- It may lead to cycling (going in circles without reaching the optimal solution).
- It requires extra iterations without improvement in the objective function.
- Multiple bases can lead to the same solution.
Concrete Example: Non-Degenerate Basic Feasible Solution
Using our maximizing problem again:
BFS at corner point (20, 30):
- Basic variables:
, - Non-basic variables:
,
Is this degenerate? NO! Both basic variables (
Concrete Example: Degenerate Basic Feasible Solution
Let's consider a different problem:
We have 3 constraints:
We have 3 constraints:
We have 5 variables:
To find basic variables we need to set
Now, suppose we get this basic feasible solution:
- Basic variables:
, , - Non-basic variables:
,
Is this degenerate? YES! One of the basic variables (
Geometric Interpretation
Non-degenerate corner point: Exactly
In 2D with 2 constraints: A non-degenerate corner point is where exactly 2 constraint lines intersect.
Degenerate corner point: More than
In 2D: If 3 or more constraint lines meet at the same point, that corner point is degenerate.
Convex Sets
A set is convex if, when you pick any two points inside it, the entire line segment connecting those two points also lies completely inside the set.
Think of it as: "no dents, no holes, no curves inward".
In simple words, we can explain the convex set as a shape. Imagine a shape or a group of points. A set is called convex if, whenever you pick any two points inside it, the straight line connecting those two points also stays completely inside the shape.
For example take these shapes:
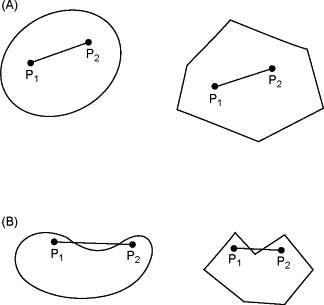
In section (A), in both shapes, the line connecting points
The shapes in section A are convex sets, while those in section B are not.
Simple Examples
Convex Sets:
- Circle: Pick any two points inside a circle, the line between them stays inside
- Square: Any line segment between two points in a square stays in the square
- Triangle: Always convex
- Any polygon without indentations (regular shapes)
- Half-space: The region defined by
- Your feasible regions from the graphical method problems!
Non-Convex Sets:
- Crescent moon: If you pick two points on opposite ends, the line between them goes outside
- Star shape: Lines between points on opposite arms go outside
- Letter "C": Connect the top and bottom of the C - the line segment is outside
- Donut/Ring: Any line through the hole exits the set
Why Feasible Regions Are Always Convex
This is a fundamental theorem in linear programming :
The feasible region of a linear programming problem is ALWAYS convex.
Why? Each constraint creates a half-space (a convex set), and the intersection of convex sets is always convex.
The Simplex Method of solving Linear Programming Problems
What is the Simplex Method?
The Simplex Method is an iterative algebraic algorithm that solves linear programming problems by systematically moving from one corner point (basic feasible solution) to another, always improving the objective function, until the optimal solution is reached.
Think of it as: Instead of graphing and checking all corners visually, the Simplex Method does this algebraically using a table (called a tableau)
Why Do We Need It?
The graphical method only works for 2 or 3 variables. For real-world problems with hundreds or thousands of variables, we need an algebraic approach. The Simplex Method can handle any number of variables.
The Algorithm of Simplex Method
Step 1: Convert to Standard Form
- Maximize (if minimizing, convert by multiplying objective by -1)
- All constraints must be equalities (add slack variables)
- All variables
- All RHS values
Step 2: Create the Initial Simplex Tableau
-
Write the problem as a table with rows for constraints and one row for the objective function.
-
Include all variables (original + slack)
Step 3: Identify the entering variable (pivot column)
-
Find the most negative entry in the objective row (bottom row).
-
The column with this entry becomes the pivot column.
-
This variable will enter the basis (become basic).
Step 4: Identify the Leaving Variable (Pivot Row)
-
Calculate minimum ratio test: Divide the elements of RHS by it's corresponding pivot column entry (dividing only positive entries from the RHS, excluding the RHS element from the objective function row).
-
The row with the smallest ratio becomes the pivot row (Ignore negative and zero values).
-
This variable will leave the basis (become non-basic)
With having both the pivot row and column pinned down, we can identify the pivot element itself.
Step 5: Perform Pivot Operation
-
Make the pivot element = 1 (divide pivot row by pivot column)
-
Make all other entries in pivot column zero (basically follow Gaussian Elimination)
Step 6: Check for optimality
-
If all entries in the objective row are
, that's the time to stop the algorithm. -
If there are still negative entries, loop back to step 3.
Step 7: Read the Solution
-
Basic variables (columns with single 1 and rest 0s) have values from RHS
-
Non-basic variables = 0
-
Objective function value is in the RHS of the objective row
Example
Let's understand the method by going though with a simple yet concrete example.
Let's solve this problem step by step:
Maximize
Subject to:
Step 1: Convert to standard form.
We do this by adding slack variables.
Objective:
Step 2: Initial Simplex Tableau
The initial variables in the basis are the 3 basic variables, chosen as
| Basis | RHS | |||||
|---|---|---|---|---|---|---|
| 2 | 1 | 1 | 0 | 0 | 18 | |
| 2 | 3 | 0 | 1 | 0 | 42 | |
| 3 | 1 | 0 | 0 | 1 | 24 | |
| -3 | -2 | 0 | 0 | 0 | 0 |
Step 3: Identify the entering variable for the basis.
Iteration 1.
First, a quick re-write of the table as a proper matrix:
The most negative variable in the row of the objective function is
This way, we identified the pivot column in the matrix, which will be used later for row operations via Gaussian Eliminations
Step 4: Identify the leaving variable for the basis.
Minimum ratio test:
- Row 1:
- Row 2:
- Row 3:
.
Minimum is
Step 5: Pivot Operations.
So we have our matrix:
I added the column names back to keep track of which is our pivot column (the one in which our entering variable is in.)
Our pivot:
Goal 1: Convert all elements in Objective row (the last row) to either zero or greater than zero.
Applying row operations:
There is still one negative value remaining, the
However before that, to make things simpler, let's reduce the pivot to 1.
We can better format the fractional values to decimal:
Before we proceed to fully eliminate the -1, we have to reduce all the other elements in the current pivot column to zero.
So,
Now, for
That concludes iteration 1.
Iteration 2
Now, we are ready to work on the objective row again.
Most negative element in objective row is
So
Now, to find the leaving variable:
- Row 1:
- Row 2:
- Row 3:
Minimum is
Now we have our new pivot sitting at row 1, column 2, which is
First we normalize the pivot to 1:
So, for
Now we still have a negative value under
Before we proceed to iteration 3, we need to reduce all the other non-pivot elements in the pivot row to zero.
For
For
This marks the end of iteration 2.
Iteration 3
Now we repeat the same process again.
Most negative element is under
That's our pivot column.
Now we test the minimum ratios:
- Row 1:
(ignoring) - Row 2:
- Row 3:
So, we have our pivot on
First we normalize the pivot.
Now, for
Now, we just need to convert the remaining non-pivot elements to zero.
Starting with
And for
Since no elements on the objective function row are less than zero, we have reached optimality and now, can stop.
Step 6: Reading the solution
We identify columns that have:
- Exactly one 1
- All other entries are 0
The candidates are:
So these are our basic variables.
We construct a proper matrix:
So,
That's our basic feasible solution.
Charnes' Big-M Method
Big-M Method : The Core Idea
The Big-M Method solves a fundamental problem: What if you can't use slack variables to get an initial basic feasible solution?
The Problem
In our previous problem, all constraints were of type:
For example:
We easily added slack variables to get our starting point (0,0).
But what if we have
Now, the problem is that we can't start at (0,0) - it violates these constraints!
The Big-M Solution: Artificial Variables
Idea: Add "artificial variables" to create a valid starting point, but make them so undesirable that they get kicked out immediately.
How? Assign them a huge penalty (M = very large number) in the objective function :
- Maximization: Add -M × (artificial variable) → makes it very bad
- Minimization: Add +M × (artificial variable) → makes it very bad
When Do You Need Big-M?
| Constraint Type | What You Add | Need Big-M? |
|---|---|---|
| ≤ | Slack variable only | ❌ No (regular Simplex) |
| ≥ | Surplus + Artificial | ✅ Yes |
| = | Artificial only | ✅ Yes |
The Big-M Algorithm (5 Steps)
Step 1: Make all RHS positive (multiply by -1 if needed)
Step 2: Convert constraints to equations:
constraint: Add slack variable constraint: Subtract surplus variable , add artificial constraint: Add artificial variable
Step 3: Modify objective function:
- Maximization:
- Minimization:
Step 4: Create initial tableau and eliminate artificial variables from Z-row.
Step 5: Solve using regular Simplex (we know this part).
Key Differences from Regular Simplex
| Aspect | Regular Simplex | Big-M Method |
|---|---|---|
| Constraints | All ≤ | Mixed (≤, ≥, =) |
| Starting variables | Slack only | Slack, surplus, artificial |
| Objective modification | None | Add penalty M |
| Initial tableau setup | Simple | Need to eliminate artificial from Z-row |
| Iterations | Same Simplex | Same Simplex |
Example
Let's cement the understanding using a concrete example
Given:
Maximize
Subject to:
Step 2: Convert constraints
- Constraint 1:
(surplus + artificial) - Constraint 2:
(that's our usual slack variable)
Step 3: Modified objective function
In standard form:
Step 4: Initial Tableau (before elimination of artificial variables)
Let the initial chosen basic variables be:
| Basis | RHS | |||||
|---|---|---|---|---|---|---|
| 1 | 1 | -1 | 1 | 0 | 4 | |
| 2 | 1 | 0 | 0 | 1 | 10 | |
| -3 | -2 | 0 | M | 0 | 0 |
Step 5: Eliminate artificial variable from Z-row.
We need to make the
So, we can go for this row operation:
Thus:
| Basis | RHS | |||||
|---|---|---|---|---|---|---|
| 1 | 1 | -1 | 1 | 0 | 4 | |
| 2 | 1 | 0 | 0 | 1 | 10 | |
| -3-M | -2-M | M | 0 | 0 | -4M |
From here on out, we can apply the The Simplex Method of solving Linear Programming Problems and solve this problem to get the correct basic variables and their solution.
Since the method is way too much calculation intensive, I won't bother with the calculations this time.
However you may have some questions remaining:
QUESTION 1: Won't M in Z-row Affect Simplex Operations?
Answer: YES, and that's exactly the point!
The M terms in the Z-row are INTENTIONAL and guide the Simplex algorithm.
How M Works During Simplex
Remember: M is assumed to be infinitely large (M → ∞)
When comparing Z-row entries for the entering variable:
text
Z-row: -3-M -2-M M 0 0
Which is most negative?
Since M is huge:
- (-3-M) is MUCH more negative than (-2-M)
- Both are MUCH more negative than 0
- M is positive
Order: (-3-M) < (-2-M) < 0 < M
So
The M Terms Stay Throughout
The M terms remain in the Z-row during iterations. They only disappear when:
- Artificial variables leave the basis (get eliminated)
- You reach the optimal solution
This is normal and expected!
QUESTION 2: Why is 0 in a1 Column Enough? There's Still a 1 Above!
Answer: The 1 is PERFECTLY FINE! That's how basic variables work.
Understanding Basic Variable Columns
Look at our final tableau after the removal of multiplier:
| Basis | RHS | |||||
|---|---|---|---|---|---|---|
| 1 | 1 | -1 | 1 | 0 | 4 | |
| 2 | 1 | 0 | 0 | 1 | 10 | |
| -3-M | -2-M | M | 0 | 0 | -4M |
The a1 column is: (reading top to bottom including Z-row) is a unit column -- exactly what we need for a basic variable!
Why the 1 is Necessary
The 1 in the a1 column (Row 1) tells us:
is in the basis (from RHS of Row 1) - The constraint equation is satisfied
This is identical to regular Simplex!
The top 1 stays - it MUST stay to indicate a1 is basic!
With that, we can conclude the Big-M method.
Duality Theory
The Core Concept
Every LP problem (called the PRIMAL) has a paired problem (called the DUAL). They're like two sides of the same coin - solving one gives you information about the other!
The Primal-dual relationship
Example to understand the concept.
Primal problem:
Maximize
Subject to:
Now the dual variant of this problem would be:
Minimize
Subject to:
How to construct the dual equation?
The Transformation Rules
Step 1: Flip the objective
- Primal
MAXbecomes DualMIN - Primal
MINbecomes DualMAX
Step 2: Transpose the coefficient matrix
- Primal rows become dual columns
- Primal columns become dual rows
Step 3: Swap coefficients and constraints
- Primal objective coefficients become dual RHS
- Primal RHS becomes dual objective coefficients
Step 4: Reverse inequalities
- Primal <= becomes dual >=
- Primal >= becomes dual <=
- Primal = stays dual =
Think of it as "Everything swaps roles"
Example
Given primal equation:
Maximize Z = 3x1 + 5x2
Subject to:
-
x1 + 2x2 <= 6
-
2x1 + x2 <= 8
-
x1, x2 >= 0
CONSTRUCT DUAL:
Step 1: Flip objective
Primal MAX → Dual MIN
Step 2: Create variables
2 constraints → 2 dual variables: y1, y2
Step 3: Dual objective
RHS values (6, 8) become coefficients
Dual: MIN G = 6y1 + 8y2
Step 4: Dual constraints
For x1 (column , objective coefficient 3):
1y1 + 2y2 >= 3
For x2 (column , objective coefficient 5):
2y1 + 1y2 >= 5
Step 5: Variable signs
Primal has <= → Dual variables >= 0
So: y1, y2 >= 0
FINAL DUAL:
Minimize G = 6y1 + 8y2
Subject to:
-
y1 + 2y2 >= 3
-
2y1 + y2 >= 5
-
y1, y2 >= 0